Chapter 2 - Data models and Query languages

Relational vs Document Models
Relational
- Been here for an eternity and still powers most of the web today
- Is easy to generalise and can then be applied to pretty much any application
- Object-Relational mismatch
- Most programming is in OOP, and SQL stores it then differently. This distortion of models is reduced by ORMs (e.g. Hibernate) but it can’t hide it completely.
- Example with Bill Gates’ CV:

- Strict schema: Schema on write. Changing schema implies migrations (requires downtime, can be slow)
NoSQL (Document)
- Greater scalability than Relational
- Large datasets
- Very high write throughput
- Specialised query operations, not well supported by Relational model
- Dynamic and expressive schema
- Example with Bill Gates’ CV:

- Model representation:

- Notice the use of IDs for region and industry
- When to use IDs or text string?
- Duplication: Do not duplicate human-meaningful information
- ID can remain, and information attached to it can change (e.g. Translations)
- When to use IDs or text string?
- How about School Names or Organisations as text and not IDs?
- Well they can be set as IDs, referencing other entities
- But support for Joins are poor in the Document model, and these relations are the core of the relational (hehe) model
- Model representation:
- If your application does use many-to-many relationships, the document model becomes less appealing
- Flexbile schema: Schema on read
- Schema-on-read is similar to dynamic (runtime) type checking in programming languages, whereas schema-on-write is similar to static (compile-time) type checking
Summary
A hybrid of the relational and document models is a good route for databases to take in the future.
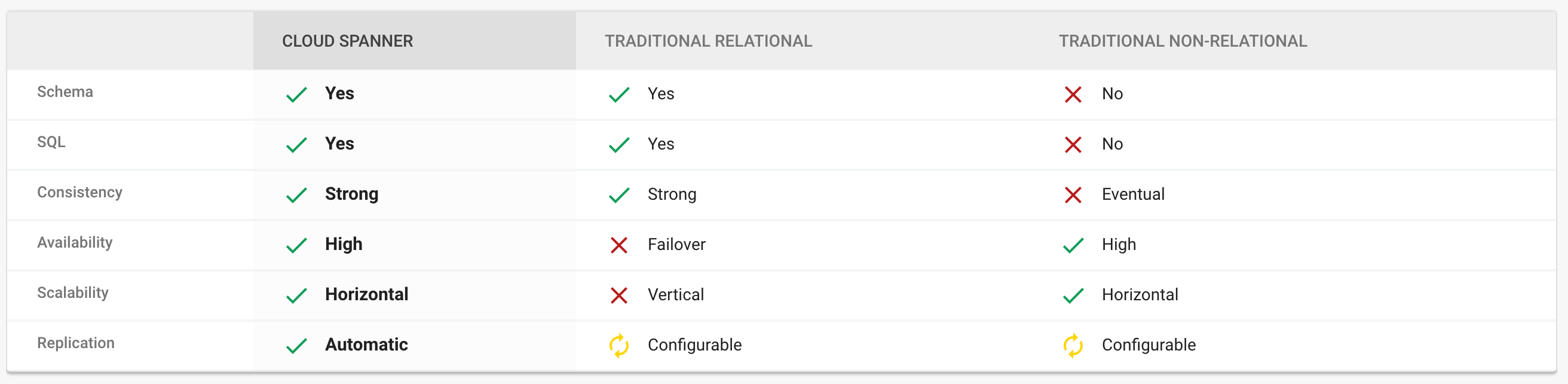
Query language for Data
Imperative
Performs operations in a certain order.
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}
Declarative
You don't specify How. For instance here, you won't control the order in which the animals within the Sharks family are returned.
SELECT * FROM animals WHERE family = 'Sharks';
MapReduce
Somewhere in between... MapReduce is a programming model for processing large amounts of data in bulk across many machines
Example with MongoDB where you want to count the number of occurences of species in the Sharks family grouped by the month when they have been observed:
db.observations.mapReduce(
function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
function reduce(key, values) {
return Array.sum(values);
},
{
query: { family: "Sharks" },
out: "monthlySharkReport"
}
);
Where:
query: { family: "Sharks" }specifies we consider shark species onlyfunction map()is called for every document matching the query, settingthisto the document objectemit(year + "-" + month, this.numAnimals)emits akey(year + "-" + month, like 2017-11) and avalue(this.numAnimals, like 12) representing the number of species.function reduce(key, values)groupskeys frommapand sumsvalues. This function is called once.- Result is then sent to the collection
monthlySharkReport.
Aggregations
Similar results than with the Mapreduce above:
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
} }
]);
Graph-Like Data Models
Graph is:
* _Vertices_ (also called _nodes_ or _entities_)
* _Edges_ (also _relationships_ or _arcs_)
Use cases:
* Social graphs: People are vertices, edges shows who knows who
* Web graphs: Web pages are vertices, links are edges
* Rail networks: Junctions are vertices, rails between them are edges
Property graphs
Example of a property graph in PostgreSQL (using json data type):
Notice directed edges read like: from
xtoy,xis called the tail, andythe head. Read more on this.
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
properties json
);
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id), # Vertex at which the edge starts
head_vertex integer REFERENCES vertices (vertex_id), # Vertex at which the edge ends
label text, # Just a label for the relation between the vertices.
properties json
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);
Querying property graphs
Also note that even though graph data can be represented in relational databases, querying it is not easy as the number of "hops" to find the vertex you're after is not known in advance.
Introducing: Cypher Query Language
Example: (Idaho) -[:WITHIN]-> (USA) represents an edge labelled WITHIN between two vertices, Idaho being the tail and USA the head.
Say we have some data like:
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)
We can then query like below to find people who emigrated from the United States to Europe.
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
Notes:
* `[:WITHIN*0..]` means "follow a `WITHIN` edge, 0 or more times"
Triple Stores and SPARQL
Very similar to property graphs, however it must be described in a three-part statement:
* `Subject`
* `Predicate`
* `Object`
Examples:
* (Jim, likes, Bananas)
* (Lucy, age, 33)
* (Lucy, married, Alain)
Subject is like a Vertex
Object is one of:
* A value, like a string or integer.
* `(Lucy, age, 33)` is then equivalent to a vertex with `properties` are `{age: 33}`
* Another vertex in the graph.
* `(Jim, likes, Bananas)` then has `likes` as a labelled edge, `Jim` (the subject) is the tail node and `Bananas` (the Object) is the head.
Querying with SPARQL
SPARQL is a query language for Triple stores using the RDF data model, based on a triple store.
Same example as above for finding emigrants from US to EU.
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}
Datalog
The foundation of them all, still used in Hadoop for example via Cascalog.
Same as triple store with a slightly different systax: predicate(subject, object)
Conclusion
- Hierarchical reprensentation came first (the big tree)
- Many-to-many relationships couldn't be represented with this: Invention of the relational model
- Difficult to scale horizontally the relational model or represent data accurately: Introduction of a new non relational model which can be split in 2 categories
- Document databases: self contained, no relations between documents
- Graph databases: everything relation